What are your core services?
Mobomo is a premier web and mobile application development company.
We have extensive experience in creating functional, large-scale, engaging mobile and responsive web designs. Our process helps to uncover the characteristics of your users by learning about their needs, wants, and limitations.
Strategy
Every great product begins with a great strategy and clear goals. Mobomo starts each project with strategy development, we don’t just take your requirements and build you a solution. We build strategy first to identify key metrics of success and ensure your mobile app and/or website will hit those performance goals and deliver a solid ROI.
Once we establish a strategy and set goals it’s important to find out about your business in depth. We’ll analyze the market, perform user interviews, review analytics, and distill the data into user stories and help you decide what steps to take next
Design
Without a thoughtful user experience, apps, websites, and big data are useless. That's why we take a user-centric design approach to every product we develop.
User experience:Your product will combine form and function so users can find the information they need quickly. We leverage usability testing tools and techniques to understand how users will interact with your product to maximize user engagement and satisfaction.
Visual design: Because research has shown that we absorb the information in images 50 times faster than text, you can count on your product to be highly visual. Our design experts move quickly from wireframe to designs to interactive prototypes to ensure brilliant product design.
Mobile first design:By designing for the device with the least real estate first, your product will focus on key functionality for users. We are experts at mobile-first development, resulting in user experiences that work on any device, anywhere, at any time.
Development
Mobile app development:Your cross-platform mobile app will enable employees to work more efficiently or customers to interact with you, no matter where they are or what mobile device they use.
Web development:Your website will not only be aligned with your business needs, but users will be able to find the information they need quickly and easily. Responsive design: Because we are in the age of the mobile device, it almost guaranteed that your website will be accessed from desktop, tablet, and smartphone. Your responsive site will provide the best user experience across devices – and it will be 508 compliant. Visit USA.gov or NASA.gov to see some of our work.
API development:Need to unlock and share data? We will build you an API that lets your employees easily access the data they need to do their jobs.
Big data visualization:We can transform all of your data into usable information via a big data visualization dashboard. Need a dynamic, configurable tool that provides live visualizations? You got it.
Cloud Computing
Do you know where your data is? You will, once it's hosted in a secure cloud environment and managed by experts.
Data migration:Our team’s deep experience with big data means we can move your files quickly, securely, and seamlessly – without disrupting your team’s work. Data management: We will clean up your data and keep it easily accessible anytime you need it. Our work developing the official U.S. Navy apps required the development of an AWS solution to aggregate information from various disparate news sources such as Navy websites, blogs, and social media from each carrier, base and fleet. These data feeds were cleansed and homogenized to create a robust web service API for the native apps and other third-party applications to use.
High performance infrastructure:One of the beautiful things about cloud hosting is having the magical ability to generate servers based on peak demand. When usage goes down, servers are removed to lower total cost of ownership. Our skilled DevOps engineers will automate and manage this for you, so you don’t even have to think about it. For NASA.gov, our team has architected a 100% Drupal 7 AWS cloud solution with security, performance, and availability in mind. It is deployed in multiple AWS availability zones for redundancy, handles over 250 content editors nationwide performing over 1,000 content updates a day, receives on average close to one million pageviews a day, and manages peaks loads of over 5,000,000 page views a day representing over 200,000 simultaneous visitors.
Shared infrastructure:Finally, Mobomo’s cloud experts design solutions to maximize investment over a large number of customers. At NASA, we have developed platforms for both Drupal-as-a-Service and WordPress-as-a-Service to enable multiple tenants to share cloud infrastructure while still ensuring high security, performance and availability.
What's your process?
Mobomo believes in a co-creation model for developing its solutions—our team partners with our clients to build solutions in a collaborative manner. This methodology allows Mobomo to deliver robust applications that meet our clients' business objectives. Mobomo's process emphasizes:
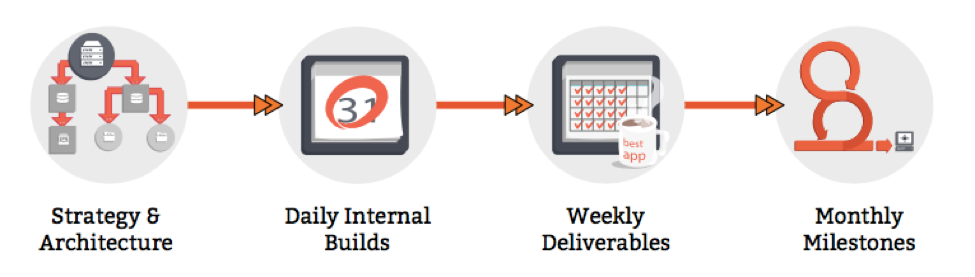
Mobomo executes this methodology using an Agile framework—iterative product development that relies on close collaboration with our clients. Iterative development is an industry best practice for mobile software development and is the approach that Mobomo has used to successfully launch over 200 products. Mobomo's proposed development methodology, illustrated in Figure 1 below, consists of three phases: Kick Off, Product Iteration, and Close Out. Because the core of our product development paradigm is co-creation, FDA will be involved in each step of the life cycle shown below. The desired product will be aligned to the FDA's strategy, business goals, priorities, and requirements.

Our next blog will be answering more questions like how to ensure your project is executed properly, portfolio of past clients and best communication tools we use with our clients.
Importance of a mobile app
Every company should find value in a digital strategy. Deciding on a mobile strategy for your business requires a number of considerations. First you may need to decide what’s right for you - a mobile application or a responsive website? When a business is determining their mobile strategy, hopefully they are thinking in terms of a mobile application or a responsive website.
Considerations for Your Budget Before you Build your Mobile App
There are many things to consider before you design and build a mobile app. For example, some questions that will need to be determined prior to kicking off your project are which platform do you want an app built on Android, iOS or both? Are you wanting a native or hybrid app? What is your internal timeline, what date would you want your mobile app to go live for users to begin engagement? All of these questions and more need to be considered before your project kick-off. We have outlined some important considerations that you will need to take into account that may affect your overall budget.
Consideration 1: Define requirements and choose feature set
Every app has different features, some compliment others while other features are not necessarily meant for an MVP product to launch it is still important to decide if you want a simple or robust feature set.
Some of the following are features that you can include in your mobile app that may affect your overall budget :
Consideration 2: Do you need design or development? Both?
Some folks have an internal design team in which case wireframes are built out and given to a development company while other companies may need a full design and development.
The cost of only design or only development or design and development differ because if you are only needing a development service and depending on the feature set your cost could be less than if you were looking for a complete design and development project.
Consideration 3: Which platform does it make more sense to launch on?
Who is the target audience that you are trying to reach? What stage in the product are you in? Do you need an app for Android or iOS or both? Building one app will be cheaper than building two apps.
Consideration 4: Scope of project or timeline of project
Are you hoping to launch your mobile app in a certain time frame? If so, this may affect the scope of the project. If you are working against a shorter timeframe such as less than 6 months you may have to launch an MVP product in order to meet your timeline. If you do not have a particular time you are hoping to launch by then you will have more time if desired to make your app more robust
Some timelines vary depending on feature set and the timeframe that you are working with - the most features you want the more folks you need on your dev team.
Consideration 5: Minimum Viable Product versus Maximum Viable Product
Some decide to launch an “minimum viable product” which means that it has just enough features to satisfy the end users because the design feature set would be limited.
Your overall cost would be lower than if you were launching a more polished app which would have more advanced feature set.
Consideration 6: Frontend & Backend Development
Some may already have backend development complete for example if the company already has a website or a web app typically the backend development can be applied. Building out the backend may not be necessary, it may only require frontend development.
If you need only the front-end versus frontend and backend development that will affect the overall cost of the mobile app development depending if you need one or the other or both. Are you constantly updating your content to the backend? This could also require for your architecture to be more robust which will increase the total cost.
Consideration 7: Hosting and Maintenance Post App Launch
Ongoing maintenance is always a good idea ADVANTAGE OF MAINTENANCE. This is typically a cost that is built into the contract and agreed upon whenever the client and company agree to the terms and contract.
Consideration 8: Compliance and accessibility
Ensuring what you are building is within the bounds of what is being designed/ developed to make sure that the company is staying compliant with your company's privacy policy. Incorporating one or more of the compliance could impact your budget depending on the level of complexity.
Timeline to design and build a mobile application
Timeline you can expect for a mobile application is the following, please keep in mind these are rough estimates and vary depending on project scope and needs.
Additional things to consider that may increase mobile app cost:
WHY YOU SHOULD CHOOSE MOBOMO?
Mobomo knows mobile. We have extensive experience in designing and developing mobile apps, our process prioritizes your target audience increasing user adoption and customer satisfaction to ultimately exceed your goals.
We take the time to carefully understand our clients needs and goals, we created an app calculator compiled of the key components that we often see that effect our clients mobile app budget.
Of course, this is just an estimation, we would love to talk through your mobile app and how we can make it awesome.
Welcome to part 2 of our exploration of the Nutch API! In our last post, we created infrastructure for injecting custom configurations into Nutch via nutchserver. In this post, we will be creating the script that controls crawling those configurations. If you haven’t done so yet, make sure you start the nutchserver:
$ nutch nutchserver
Dynamic Crawling
We’re going to break this us into two files again, one for cron to run and the other that holds a class that does the actual interaction with nutchserver. The class file will be Nutch.py and the executor file will be Crawler.py. We’ll start by setting up the structure of our class in Nutch.py:
import time
import requests
from random import randint
class Nutch(object):
def __init__(self, configId, batchId=None):
pass
def runCrawlJob(self, jobType):
pass
We’ll need the requests module again ($ pip install requests on the command line) to post and get from nutchserver. We’ll use time and randint to generate a batch ID later. The function crawl is what we call to kick off crawling.
Next, we’ll get Crawler.py setup. We’re going to use argparse again to give Crawler.py some options. The file should start like this:
# Import contrib
import requests
import argparse
import random
# Import custom
import nutch
parser = argparse.ArgumentParser(description="Runs nutch crawls.")
parser.add_argument("--configId", help="Define a config ID if you just want to run one specific crawl.")
parser.add_argument("--batchId", help="Define a batch ID if you want to keep track of a particular crawl. Only works in conjunction with --configId, since batches are configuration specific.")
args = parser.parse_args()
We’re offering two optional arguments for this script. We can set --configId to run a specific configuration and setting --batchId allows us to track as specific crawl for testing or otherwise. Note: with our setup, you must set --configId if you set --batchId.
We’ll need two more things: a function to make calling the crawler easy and logic for calling the function. We’ll tackle the logic first:
if args.configId:
if args.batchId:
nutch = nutch.Nutch(args.configId, args.batchId)
crawler(args.job, nutch.getNodeID())
else:
nutch = nutch.Nutch(args.configId)
crawler(args.job, nutch.getNodeID())
else:
configIds = requests.get("http://localhost:8081/config")
cids = configIds.json()
random.shuffle(cids)
for configId in cids:
if configId != "default":
nutch = nutch.Nutch(configId)
crawler(nutch)
If a configId is given, we capture it and initialize our Nutch class (from Nutch.py) with that id. If a batchId is also specified, we’ll initialize the class with both. In both cases, we run our crawler function (shown below).
If neither configId nor batchId is specified, we will crawl all of the injected configurations. First, we get all of the config ID’s that we have injected earlier (see Part 1!). Then, we randomize them. This step is optional but we found that we tend to get more diverse results when initially running crawls if Nutch is not running them in a static order. Last, for each config ID, we run our crawl function:
def crawler(nutch):
inject = nutch.runCrawlJob("INJECT")
generate = nutch.runCrawlJob("GENERATE")
fetch = nutch.runCrawlJob("FETCH")
parse = nutch.runCrawlJob("PARSE")
updatedb = nutch.runCrawlJob("UPDATEDB")
index = nutch.runCrawlJob("INDEX")
You might wonder why we’ve split up the crawl process here. This is because later, if we wish, we can use the response from the Nutch job to keep track of metadata about crawl jobs. We will also be splitting up the crawl process in Nutch.py.
That takes care of Crawler.py. Let’s now fill out our class that actually controls Nutch, Nutch.py. We’ll start by filling out our __init__ constructor:
def __init__(self, configId, batchId=None):
# Take in arguments
self.configId = configId
if batchId:
self.batchId = batchId
else:
randomInt = randint(0, 9999)
self.currentTime = time.time()
self.batchId = str(self.currentTime) + "-" + str(randomInt)
# Job metadata
config = self._getCrawlConfiguration()
self.crawlId = "Nutch-Crawl-" + self.configId
self.seedFile = config["meta.config.seedFile"]
We first take in the arguments and create a batch ID if there is not one. The batch ID is essential as it links the various steps of the process together. Urls generated under one batch ID must be fetched under the same ID for they will get lost, for example. The syntax is simple, just [Current Unixtime]-[Random 4-digit integer].
We next get some of the important parts of the current configuration that we are crawling and set them for future use. We’ll query the nutchserver for the current config and extract the seed file name. We also generate a crawlId for the various jobs we’ll run.
Next, we’ll need a series of functions for interacting with nutchserver. Specifically, we’ll need one to get the crawl configurations, one to create jobs, and one to check the status of a job. The basics of how to interact with Job API can be found at https://wiki.apache.org/nutch/NutchRESTAPI, though be aware that this page is not complete in it’s documentation. Since we referenced it above, we’ll start with getting crawl configurations:
def _getCrawlConfiguration(self):
r = requests.get('http://localhost:8081/config/' + self.configId)
return r.json()
This is pretty simple: we make a request to the server at /config/[configID] and it returns all of the config options. Next, we’ll get the job status:
def _getJobStatus(self, jobId):
job = requests.get('http://localhost:8081/job/' + jobId)
return job.json()
This one is also simple: we make a request to the server at /job/[jobId] and it returns all the info on the job. We’ll need this later to poll the server for the status of a job. We’ll pass it the job ID we get from our create request, shown below:
def _createJob(self, jobType, args):
job = {'crawlId': self.crawlId, 'type': jobType, 'confId': self.configId, 'args': args}
r = requests.post('http://localhost:8081/job/create', json=job)
return r
Same deal as above, the main thing we are doing is making a request to /job/create, passing it some JSON as the body. The requests module has a nice built-in feature that allows you to pass a python dictionary to a json= parameter and it will convert it to a JSON string for you and pass it to the body of the request.
The dict we are passing has a standard set of parameters for all jobs. We need the crawlId set above; the jobType, which is the crawl step we will pass into this function when we call it; the configId, which is the UUID we made earlier; last, any job-specific arguments--we’ll pass these in when we call the function.
The last thing we need is the logic for setting up, keeping track of, and resolving job creation:
def runCrawlJob(self, jobType):
args = ""
if jobType == 'INJECT':
args = {'seedDir': self.seedFile}
elif jobType == "GENERATE":
args = {"normalize": True,
"filter": True,
"crawlId": self.crawlId,
"batch": self.batchId
}
elif jobType == "FETCH" or jobType == "PARSE" or jobType == "UPDATEDB" or jobType == "INDEX":
args = {"crawlId": self.crawlId,
"batch": self.batchId
}
r = self._createJob(jobType, args)
time.sleep(1)
job = self._getJobStatus(r.text)
if job["state"] == "FAILED":
return job["msg"]
else:
while job["state"] == "RUNNING":
time.sleep(5)
job = self._getJobStatus(r.text)
if job["state"] == "FAILED":
return job["msg"]
return r.text
First, we’ll create the arguments we’ll pass to job creation. All of the job types except Inject require a crawlId and batchId. Inject is special in that the only argument it needs is the path to the seed file. Generate has two special options that allow you to enable or disable use of the normalize and regex url filters. We’re setting them both on by default.
After we build args, we’ll fire off the create job. Before we begin checking the status of the job, we’ll sleep the script to give the asynchronous call a second to come back. Then we make a while loop to continuously check the job state. When it finishes without failure, we end by returning the ID.
And we’re finished! There are a few more things of note that I want to mention here. An important aspect of the way Nutch was designed is that it is impossible to know how long a given crawl will take. On the one hand, this means that your scripts could be running for several hours at time. However, this also means that it could be done in a few minutes. I mention this because when you first start crawling and also after you have crawled for a long time, you might start seeing Nutch not crawl very many links. In the first case, this is because, as I mentioned earlier, Nutch only crawls the links in the seed file at first, and if there are not many hyperlinks on those first pages, it might take two or three crawl cycles before you start seeing a lot of links being fetched. In the latter case, after Nutch finishes crawling all the pages that match your configuration, it will only recrawl those pages after a set interval. You can modify how this process works, but it will mean that after awhile you will see crawls that only fetch a handful of links.
Another helpful note is that the Nutch log at /path/to/nutch/runtime/local/logs/hadoop.log is great for following the process of crawling. You can set the output depth of most parts of the Nutch process at /path/to/nutch/conf/log4j.properties (you will have to rebuild Nutch if you change this by running ant runtime at the Nutch root).

Mobomo's CEO, Brian Lacey, was recently featured in a new research report about how UX impacts browsing behavior.
The report was published by Clutch, a leading B2B ratings and reviews firm in Washington, DC.
Mobomo is currently ranked as a Top 10 UX agencies in Washington D.C. on Clutch.
User experience encompasses all end-user interaction with a website. Good UX means a site is easy to navigate and designed with a clear interface. UX enhances the content on a page, but certain usability pitfalls can lead to a decline in web traffic.
Clutch surveyed over 600 people who visit five or more websites every month. They found that over half of people will leave a website for a particular session if it’s unreliable (54%) or slow to load (53%).
Unreliable pages prevent people from reaching the content they desire by presenting error messages, broken links, or a glitchy interface.
We know people are accustomed to getting the online content they want immediately, particularly now that mobile searches outnumber desktop searches.
Mobomo Tackles Mobile Web Challenges
More than half of people (52%) will abandon a slow website for good. With mobile, users expect to have answers to their most pressing questions at their fingertips. A page’s speed can determine where those users will turn with their queries.
Lacey identified speed as the main challenge when designing for the mobile web.
“You can never control how someone is going to be able to connect; if they’re on 3G or on the metro,” Lacey said. “The ability to get someone the results they need at that exact second without having to download a million libraries is the most important part of mobile web user experience.”
Lacey also commented on the price companies will pay if they do not prioritize speed on the mobile web.
“With so many distractions out there, if someone has to wait more than three seconds, they’re going to exit out and do something else.”
People are accustomed to getting the content they want immediately, and we provide creative user experience solutions for mobile browsers. When we designed for NASA’s 2017 solar eclipse coverage, we made sure we could accommodate the most trafficked federal event online to date.
What About Apps?
Nearly two-thirds (63%) of people won’t return to a website if it’s consistently unreliable. If a page functions well on a desktop browser but not on mobile, it could lead to a significant decline in traffic.
Since growth in mobile app session activity is on the decline, web design companies must meet the rising demand for functional and reliable mobile web pages.
“If you look at general trends in the app store, people used to download 10 mobile apps a month. Now it’s down to two a year,” Lacey said. “Rarely does a user go explore for a mobile app unless there’s a specific reason such as a marketing campaign driving downloads.”
We’re meeting this challenge by focusing app development efforts in the business to business space
“As a mobile developer, we mostly have moved a lot of our services to business to business apps or apps that help with people doing their job, more vocational type things. Business to consumer apps that are outside of games are just kind of on the decline because of that.”
Mobomo continues to lead among design agencies in Washington, D.C., and we are excited to have Brian share his wisdom on Clutch.
[pdfviewer width="100%" height="849px" beta="true/false"]https://mobomo.s3.amazonaws.com/uploads/2018/08/Client-Conversations-Revision.pdf[/pdfviewer]

Federal agencies are no strangers to cyber threats, but the complexity and frequency of bot attacks have escalated dramatically. A recent incident encountered by one of our customers highlights how even with industry-leading cloud infrastructure and content delivery networks, malicious actors are finding new ways to break through. By sharing this story and strategies that worked, we hope to arm federal IT and security professionals with actionable insights to stay ahead of evolving threats.
The Evolving Threat Landscape
Cyber adversaries today are no longer hobbyists; they’re often well-funded, well-organized, and in some cases, state-sponsored. As described by TechRadar, one such campaign known as RoundPress was attributed to Russian state-backed actors. These attackers exploited vulnerabilities in webmail platforms to infiltrate governments and military agencies across the globe.
Meanwhile the use of generative AI has opened a new front in cyber deception. According to a report by Reuters, the FBI recently warned that malicious actors are using AI-generated audio and video to impersonate senior US officials, an alarming development aimed at phishing sensitive information from government personnel.
Case Study: A Federal Agency’s Strategic Response
One of the agencies we support recently faced a surge in traffic to their public-facing site. At first glance, the traffic appeared random, but a closer look revealed something more nefarious.
Traffic logs showed a flood of requests from a narrow set of IP addresses, linked to U.S.-based cloud infrastructure. The attackers had deployed a sophisticated disguise: each request masqueraded as a different device by generating thousands of randomized user-agent strings, many completely fabricated combinations of device types and browser versions that don't exist in the real world. This digital camouflage was specifically engineered to slip past traditional security filters that rely on identifying known bot signatures. It's a textbook advanced bot attack: rapid, obfuscated, and evasive.
Recognizing that IP-based blocking would be ineffective against this type of attack where IP addresses can be rapidly rotated, the team took a different approach. Through careful analysis, they identified the underlying patterns within the seemingly random user-agent strings discovering that despite thousands of variations, the attackers were actually using a limited set of device types and browser versions mixed together. Armed with this insight, they customized the Akamai Site Shield configuration to detect these specific patterns in the malformed user-agent strings, successfully filtering out malicious traffic while maintaining access for legitimate users.
The Enduring Threat of DDoS: Old Tactics, New Tricks
While bot attacks are becoming more nuanced and evasive, they are also being deployed in more traditional ways such as Distributed Denial-of-Service (DDoS) attacks. In these scenarios, large networks of compromised devices, known as botnets, are coordinated to flood systems with traffic in an attempt to exhaust bandwidth, crash applications, or take services offline. What makes today’s DDoS attacks harder to detect is the sophistication of the bots themselves. Rather than sending repetitive or obvious traffic, these bots mimic legitimate users by rotating IP addresses, randomizing payloads, and encrypting traffic to avoid detection. In some cases, attackers even use reputable cloud infrastructure to deliver attacks, making it difficult to distinguish malicious activity from genuine usage. DDoS is no longer just a blunt instrument; it has evolved into a calculated tactic that can serve as a smokescreen for more targeted intrusions elsewhere in the environment. Against this backdrop of escalating threats, federal agencies need to modernize their defensive posture with a multi-layered approach.
Strategies Federal Agencies Can Use
- Embrace Zero Trust Architecture:
Traditional perimeter-based security models are no longer sufficient in today’s threat environment. Zero Trust Architecture (ZTA) has emerged as a powerful framework that assumes no actor (internal or external) should be inherently trusted. For federal agencies, this means verifying every connection and continuously validating user identities, device integrity, and access permissions before granting access to resources.
Implementing Zero Trust at scale requires a shift in mindset and tooling. Agencies should prioritize identity and access management (IAM), implement network micro-segmentation, and leverage endpoint detection and response (EDR) technologies. Adopting this approach reduces lateral movement within networks and helps contain breaches before they escalate, aligning with federal cybersecurity mandates like Executive Order 14028.
- Implement Bot Management Tools:
Not all bots are malicious. Some, like search engine crawlers or page-loading bots used by large language models (LLMs), serve useful purposes. These types of automated traffic, while often detected as bots, are legitimate and should be allowed through.
But bad bots can wreak havoc: scraping sensitive content, executing credential-stuffing attacks, or overloading systems with fake traffic. These bots have become increasingly sophisticated, often mimicking legitimate users by rotating IP addresses, randomizing user-agent strings, or operating through residential proxies to evade detection.
Bot management tools use behavior analysis, machine learning, and fingerprinting techniques to detect and mitigate unwanted traffic in real time. Federal agencies should evaluate solutions that can distinguish between helpful and harmful bots, adapt to evolving evasion tactics, and preserve a seamless experience for legitimate users. The goal isn’t to block everything; it’s to know what’s coming through the door.
- Monitor Continuously and Share Threat Intelligence:
Cybersecurity isn’t a set-it-and-forget-it operation. Agencies must monitor their networks, applications, and endpoints continuously to detect anomalies and respond swiftly. Tools like Security Information and Event Management (SIEM) platforms and Endpoint Detection and Response (EDR) systems allow real-time visibility and correlation across complex environments.
Equally important is collaboration. As legacy programs like CISA’s EINSTEIN are phased out, agencies are turning to more modern, dynamic approaches such as the Continuous Diagnostics and Mitigation (CDM) program. CDM provides tools for real-time asset visibility, vulnerability management, and threat response, offering agencies a more flexible and proactive defense model.
Agencies can also strengthen their resilience by engaging with public-private partnerships like the Information Technology Sector Coordinating Council (IT-SCC), which fosters information sharing and cybersecurity best practices. Looking ahead, CISA’s development of the Joint Collaborative Environment (JCE) aims to further enhance collective defense through shared situational awareness and threat intelligence. As attacks grow more sophisticated, proactive monitoring and coordinated defense remain essential pillars of national cyber resilience.
- Fortify your APIs:
API’s are the connective tissue of modern government digital services, and that makes them a high-value target for adversaries. Attackers increasingly exploit vulnerable or forgotten APIs to bypass front-end protections, exfiltrate data, or inject malicious commands. The risk is especially high with “rogue APIs” (interfaces that are unmonitored, deprecated, or created outside of centralized governance processes).
Recent insights from the DoD Modernization Exchange underscored the need for full API visibility and governance across the enterprise. Whether using commercial API gateways or internal tooling, agencies must inventory all APIs, enforce consistent security policies, and monitor behavior for unusual access patterns. Rate limiting, token validation, and real-time analytics can help prevent abuse. API governance should be treated with the same urgency as endpoint and network security.
Conclusion
Sophisticated bot attacks aren’t going away; but with smarter tools, collaborative threat sharing, and adaptive defense strategies, federal agencies can outpace even the most advanced adversaries. The key is to move beyond static defenses and adopt agile, behavior-based approaches that evolve with the threat landscape.
When the bots come knocking, you don’t need to panic. You just need to be prepared.
About Mobomo, LLC
Mobomo, a private company headquartered in the D.C. metro area, is a CMMI Dev Level 3, ISO 9001:2015, and CMMC Level 1 provider of digital transformation system integration services. A premier provider of mobile, web, infrastructure, and cloud applications to federal agencies and large enterprises, Mobomo combines leading-edge technology with human-centered design and strategy to craft next generation digital experience. From private sector companies to government agencies, we have amassed deep expertise helping our clients enhance and expand their existing web and mobile suite. Interested in learning more about Mobomo? Take a tour of our capabilities, our portfolio of work, the team members who make our clients look so fantastic, and feel free to reach out with any questions you might have.