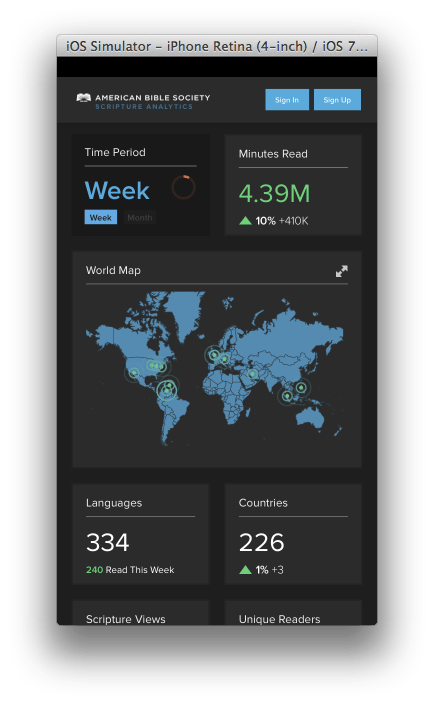
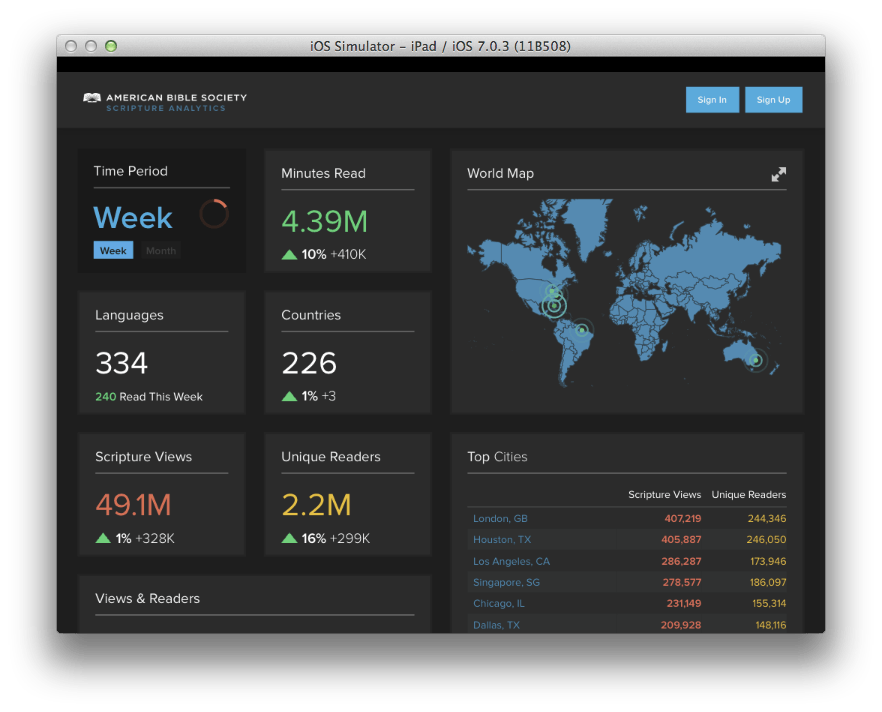
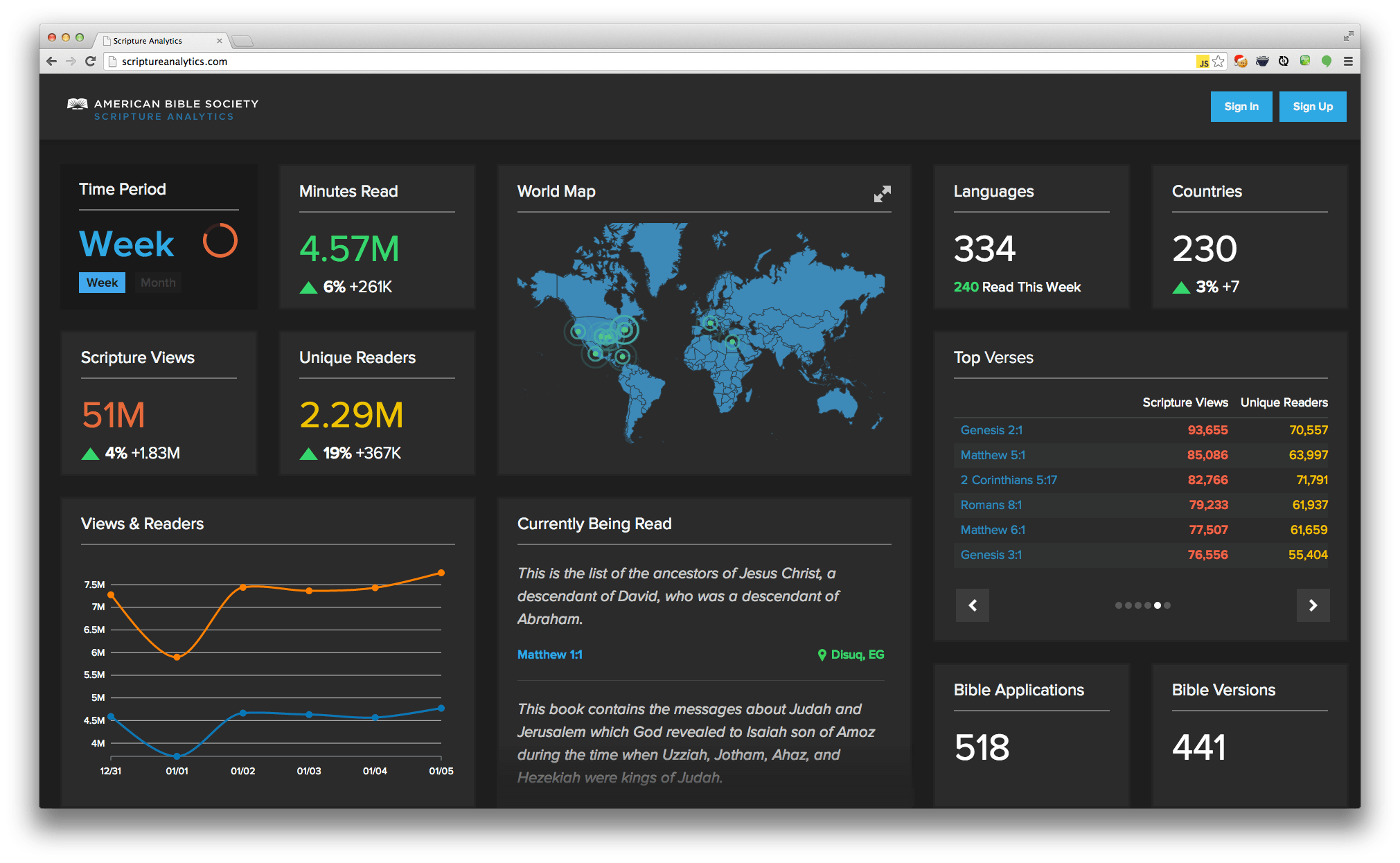
Trying to get up to speed with D3 can be a daunting task. A quick google search will reveal hundreds of different starting points, almost all of which involve writing great swaths of code in order to build even the most basic of charts. Don't believe me? Here's the official example for a basic line chart. D3's biggest barrier to entry is its biggest strength - the flexibility that it provides to create nearly any sort of visualization that you can imagine.
In order to help foster good practices (by creating re-usable charts) and to give back to a community that is so willing to share its knowledge, Intridea has released a library that will help you get started much more easily: the D3 Fakebook. With just a few lines of code, you can easily render that same bar chart:
// From the D3 Basic Line Chart example: http://bl.ocks.org/mbostock/3883245 d3.tsv('examples/data/aapl_stock.tsv', function(error, data) { var chart = new D3Fakebook.TimeScaleLineChart('#singleLine', { data : data, valueName : 'close' }); chart.render(); }); 
Easy as pie.
Getting Started
There are a few ways you can start using this library today: the first is that you can install it using bower ($ bower install d3-fakebook), which will pull down the dependencies (underscore.js and d3). You can also grab the files directly - there are both compiled JavaScript files as well as CoffeeScript.
Once you have the files loaded in your browser, you can access the different chart types under the D3Fakebook namespace. Each chart type takes a set of options that allows you to configure.
Wait - "Fakebook"? What’s up with the name?
The concept of a "fakebook" comes from Jazz - back in the 1950's, popular Jazz songs (also known as standards) were often compiled in to collections of books. Each song's transcription would have chord changes and the main melody would be written out, but not the whole song, since the musicians would make each their own by improvising on top of the chord changes.
Our goal with the D3 Fakebook is to do precisely that - give you a starting point to make amazing, beautiful visualizations that are purely your own. The Fakebook gives you a starting point and some guidance, but doesn’t force you to follow any specifically set path.
Follow the Changes
This is a living library, something we're using in our own projects (check it out in action on http://humanprogress.org) and though it's a bit rudimentary right now, we'll be adding more charts in the near future. If you want to help out, or if you've found a bug, feel free to submit a pull request on Github, and we'll incorporate it as soon as possible!
A few more roadmap items: we intend to add AMD support, compiled JavaScript modules (in addition to making the existing CoffeeScript files into actual modules), and nicer transitions.
Keep the conversation going! We'd love to hear from you!